

この章のコードはSample_SQL6.txtを使用します。
SQLではキーワード「SELECT」の次に「DISTINCT」を付加することによって検索後の重複行を除去することができます。
書式は下記のとおりです。
<書式6.1>
SELECT DISTINCT <列名1>,<列名2>,… FROM <テーブル名>;
<書式6.1>の事例を紹介する前に、テーブル「Staff」から従業員の所属部門IDと性別の列を検索するSQLを考えてみます。
<SQL例6.1>
SELECT
“Department_ID“,
“Gender“,
FROM “Staff“;
【<SQL例6.1>の実行結果】
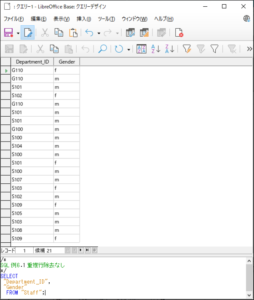
これでテーブル「Staff」に登録されている従業員の所属部門IDと性別が分かりますが、重複行を除去したほうが、資料として分りやすくなります。
重複行を除去した例は下記のとおりです。
<SQL例6.2>
SELECT DISTINCT
“Department_ID“,
“Gender“,
FROM “Staff“;
【<SQL例6.2>の実行結果】
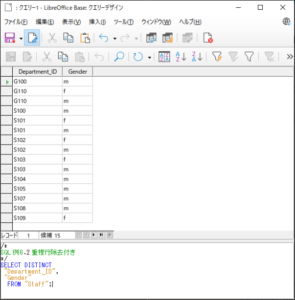
これで資料として分りやすい結果になりました。なお、検索結果は列「Department_ID」、「Gender」の順にそれぞれ昇順に並べ替えられています。