

この章のサンプルSQLコードはSample_SQL4.txtを使用します。
関数とは
与えられた値をもとに、定められた独自の処理を実行し、その結果の値を返す命令のことを関数といいます。与える(入力する)値を「引数」、返される(出力される)値を「戻り値」と呼びます。
集約関数はSELECT句に限定して使用できますが、他の関数はSQL文中の各句で使用することができます。ただし、この章では集約関数以外もSELECT句で使用して、戻り値を検証することにします。
(注)LibreOfficeのWordやCalcにも関数がありますが、BaseのSQLで使用する関数とは異なるものです。したがって、それぞれ文法や書式も異なりますので、ヘルプ情報を参照する場合に注意が必要です。
関数の基本書式
関数の基本的な書式は下記のとおりです。例外がありますが、殆どの関数は関数名の次に「()」(括弧)を記述します。引数は「()」の中に記述し、関数によって引数の数が違います。また、関数によっては省略可能な引数もあります。引数は左から順に第1引数、第2引数、・・・と呼びます。
<書式4.1>
<関数名>(<第1引数>,<第2引数>,…)
関数は入れ子構造にすることができます。下記は2つの関数を入れ子構造にした書式です。
<書式4.2>
<関数名1>(<関数名2>(<関数2の第1引数>,<関数2の第2引数>,…),<関数1の第2引数>,…)
(注)上記書式は関数1の第1引数に関数2をはめ込んで入れ子にしています。
文字列関数
文字列を操作する関数を紹介します。例にあげるSQLは実務的ではありませんが、各関数が引数の値をどのように処理するか理解しやすいように記述しています。実務的に応用する場合は引数<対象の文字列>に列名を指定して、検索するテーブルの列(フィールド)に格納された値を処理します。
LENGTH関数
ある文字列の文字数を取得します。
<構文> LENGTH(<対象の文字列>)
<戻り値> 対象の文字列の文字数
<SQL例4.1>
SELECT LENGTH(‘ABCあいう012’) FROM “z“;
(注)指定したテーブル「z」は、前章でも述べたように、SQL文の文法エラーを避けるためのもので、ダミーのテーブルです。
【<SQL例4.1>の実行結果】
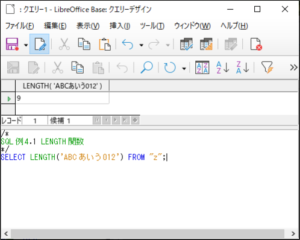
この例のように、文字列は半角文字でも全角文字でも1文字としてカウントします。
RIGHT関数・LEFT関数
RIGHT関数はある文字列の右端から指定した文字数分だけを取り出します。
また、LEFT関数はある文字列の左端から指定した文字数分だけを取り出します。
<RIGHT関数>
<構文> RIGHT(<対象の文字列>,<取得する文字数>)
<戻り値> 対象の文字列の右から、取得する文字数分の文字列
<LEFT関数>
<構文> LEFT(<対象の文字列>,<取得する文字数>)
<戻り値> 対象の文字列の左から、取得する文字数分の文字列
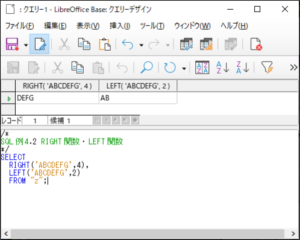
<SQL例4.2>
SELECT
RIGHT(‘ABCDEFG’,4),
LEFT(‘ABCDEFG’,2)
FROM “z“;
【<SQL例4.2>の実行結果】
RTRIM関数
ある文字列の右端から、空白(半角スペースのみ)を取り除きます。
<構文> RTRIM(<対象の文字列>)
<戻り値> 対象の文字列の右端から空白を取り除いた文字列
<SQL例4.3>
SELECT ’→’ || RTRIM(‘ Hello!! BASE SQL World. ’) || ’←’ FROM “z“;
(注)関数の前後にリテラル「’→’」と「’←’」を連結しているのは処理対象の文字列より空白が削除された事を検証するためです。
【<SQL例4.3>の実行結果】
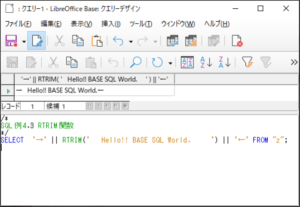
対象の文字列の「.」(ピリオド)より右側の空白が削除され、「←」が続いているのが確認できます。
LTRIM関数
ある文字列の左端から、空白(半角スペースのみ)を取り除きます。
<構文> LTRIM(<対象の文字列>)
<戻り値> 対象の文字列の左端から空白を取り除いた文字列
<SQL例4.4>
SELECT ’→’ || LTRIM(‘ Hello!! BASE SQL World. ’) || ’←’ FROM “z“;
【<SQL例4.4>の実行結果】
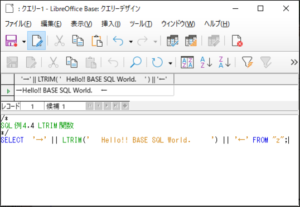
対象の文字列の「H」より左側の空白が削除され、「→」に続いて「Hello…」と文字列が続いているのが確認できます。
REPLACE関数
ある文字列の中から特定の文字列を別の文字列に置換します。
<構文> REPLACE(<対象の文字列>,<検索文字列>,<置換後文字列>)
<戻り値> 対象の文字列の中から検索文字列に該当する部分を置換後文字列に置き換えたのちの文字列全体
<SQL例4.5>
SELECT REPLACE(‘Hello!! BASE SQL World.’,’Hello’,’Let’’s Learn’) FROM “z“;
【<SQL例4.5>の実行結果】
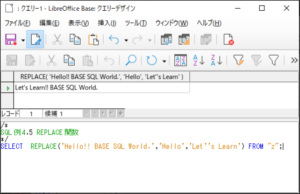
対象の文字列の「Hello」が「Let’s Learn」に置換されているのが確認されます。
SUBSTRING関数
ある文字列の中から指定した開始位置から指定した文字数分を取得します。
<構文> SUBSTRING(<対象の文字列>,<開始位置>,<取得文字数>)
<戻り値> 対象の文字列の中から開始位置から取得文字数分だけを切り取った文字列
<SQL例4.6>
SELECT SUBSTRING(‘LibreOfficeには便利な機能が豊富にあります’,14,5) FROM “z“;
【<SQL例4.6>の実行結果】
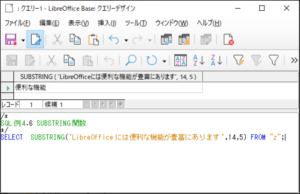
14文字目の「便」から開始して5文字の「便利な機能」が切り取られているのが確認されます。
UPPER関数
ある文字列中の英字を大文字に変換します。
<構文> UPPER(<対象の文字列>)
<戻り値> 対象の文字列の中の英字を大文字に変換した文字列
<SQL例4.7>
SELECT UPPER(‘LibreOfficeにはWriterやCalcなど、6つのコンポーネントがあります’) FROM “z“;
【<SQL例4.7>の実行結果】
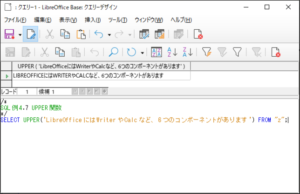
文字列中の英字が全て大文字に変換されているのが確認されます。
LOWER関数
ある文字列中の英字を小文字に変換します。
<構文> LOWER(<対象の文字列>)
<戻り値> 対象の文字列の中の英字を小文字に変換した文字列
<SQL例4.8>
SELECT LOWER(‘LibreOfficeにはWriterやCalcなど、6つのコンポーネントがあります’) FROM “z“;
【<SQL例4.8>の実行結果】
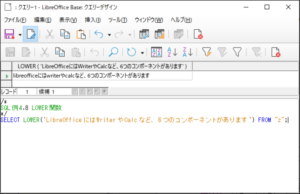
文字列中の英字が全て小文字に変換されているのが確認されます。
日付・時刻関数
日付や時刻を操作する関数を紹介します。ここではテーブル「Employee」の生年月日を例とします。
YEAR関数
ある日付の値から、年の部分だけを取り出します。
<構文> YEAR(<対象の日付値>)
<戻り値> 対象の日付値の年の部分(数値)
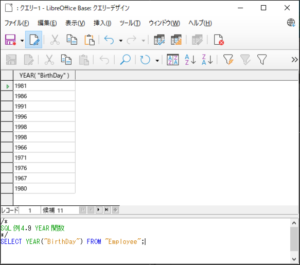
<SQL例4.9>
SELECT YEAR(”BirthDay”) FROM “Employee“;
【<SQL例4.9>の実行結果】
MONTH関数
ある日付の値から、月の部分だけを取り出します。
<構文> MONTH(<対象の日付値>)
<戻り値> 対象の日付値の月の部分(数値)
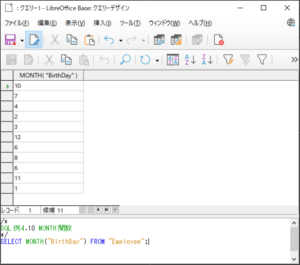
<SQL例4.10>
SELECT MONTH(”BirthDay”) FROM “Employee“;
【<SQL例4.10>の実行結果】
DAY関数
ある日付の値から、日の部分だけを取り出します。
<構文> DAY(<対象の日付値>)
<戻り値> 対象の日付値の日の部分(数値)
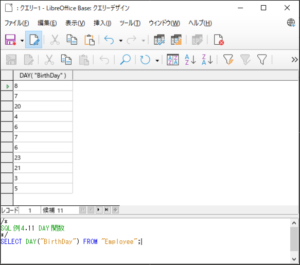
<SQL例4.11>
SELECT DAY(”BirthDay”) FROM “Employee“;
【<SQL例4.11>の実行結果】
変換関数
ある値を別の型に変換する関数を紹介します。実行結果を見てもさほど違いがないようにみえますが、数値型の値を文字型に変換した後に文字列加工したり、文字型の値を数値型に変換した後に演算する場合に威力を発揮します。
CAST関数
ある値を別の型に変換します。第1引数に変換対象の値を記述し、「AS」の次に変換後の型を指定します。
<構文> CAST(<変換対象の値> AS <変換後の型>)
<戻り値> 変換対象の値を変換後の型に変換した値
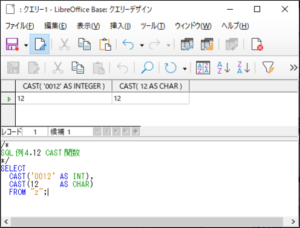
<SQL例4.12>
SELECT
CAST(’0012’ AS INT),
CAST(12 AS CHAR)
FROM “z“;
【<SQL例4.12>の実行結果】
数値関数
数値を扱う関数を紹介します。
ROUND関数
ある値を算術丸め(四捨五入)します。第1引数に対象の値を記述し、第2引数に有効桁数を指定します。有効桁数は正の値を指定した場合は小数点から右の桁数、0を指定した場合は小数点位置、負の値を指定した場合は小数点から左の桁数を表します。
<構文> ROUND(<対象の値>,<有効桁数>)
<戻り値> 対象の値を有効桁数で算術丸めした値
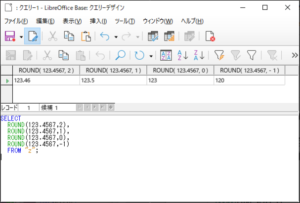
<SQL例4.13>
SELECT
ROUND(123.4567,2),
ROUND(123.4567,1),
ROUND(123.4567,0),
ROUND(123.4567,-1)
FROM “z“;
【<SQL例4.13>の実行結果】
POWER関数
ある値を階乗します。
<構文> POWER(<対象の値>,<階乗数>)
<戻り値> 対象の値を指定した数で階乗した値
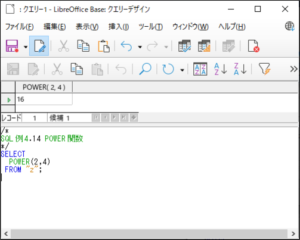
<SQL例4.14>
SELECT
POWER(2,4)
FROM “z“;
【<SQL例4.14>の実行結果】
SQRT関数
ある値の平方根を求めます。
<構文> SQRT(<対象の値>)
<戻り値> 対象の値の平方根
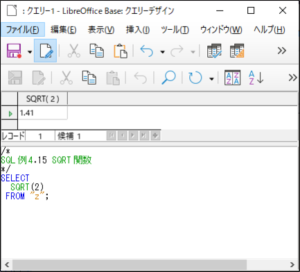
<SQL例4.15>
SELECT
SQRT(2)
FROM “z“;
【<SQL例4.15>の実行結果】
CEILING関数
ある値の小数点以下の値を切り上げます。
<構文> CEILING(<対象の値>)
<戻り値> 対象の値の小数点以下の値を切り上げた値
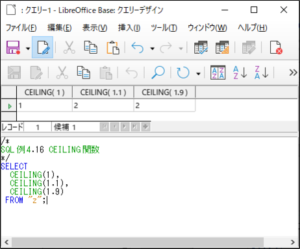
<SQL例4.16>
SELECT
CEILING(1),
CEILING(1.1),
CEILING(1.9)
FROM “z“;
【<SQL例4.16>の実行結果】
FLOOR関数
ある値の小数点以下の値を切り捨てます。
<構文> FLOOR(<対象の値>)
<戻り値> 対象の値の小数点以下の値を切り捨てた値
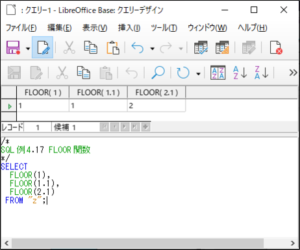
<SQL例4.17>
SELECT
FLOOR(1),
FLOOR(1.1),
FLOOR(2.1)
FROM “z“;
【<SQL例4.17>の実行結果】
MOD関数
ある値を除数で除した余りを取得します。
<構文> MOD(<対象の値>,<除数>)
<戻り値> 除算の余りの値
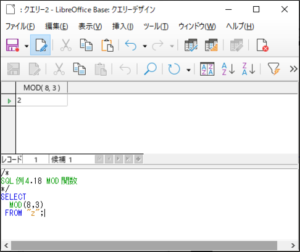
<SQL例4.18>
SELECT
MOD(8,3)
FROM “z“;
【<SQL例4.18>の実行結果】
RAND関数
0から1までのランダムな数値(乱数)を発生させます。引数に値を指定することができますが、複雑なので指定しなくて結構です。
<構文> RAND()
<戻り値> 乱数値
<SQL例4.19>
SELECT
RAND(),
RAND(),
RAND()
FROM “z“;
【<SQL例4.19>の実行結果】
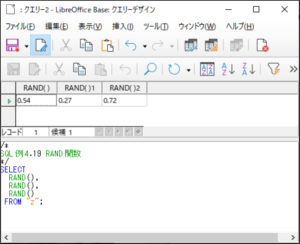
RAND関数を実行するたびに異なった乱数が発生しているのが確認されます。
入れ子構造にした関数の例
2つの関数を入れ子構造にした例を紹介します。
<SQL例4.20>
SELECT
MOD(RAND()*10,6)+1 AS “サイコロの目“
FROM “z“;
【<SQL例4.20>の実行結果】
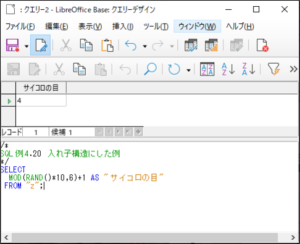
上図は一度実行した結果ですが、同じSQLを実行するたびに1~6のいずれかの数字が結果として表示されます。
今回はSQL文が少し複雑になりましたので、解説しましょう。
①関数「MOD()」は第1引数が「RAND()*10」、第2引数が「6」です。
②第1引数「RAND()*10」は関数「RAND()」の戻り値として0~1まで発生する乱数を10倍して0~10まで発生するようにし、その値を第1引数に代入します。
③次に第1引数の値を第2引数「6」で割り、その余り(整数)を求めると関数「MOD()」の戻り値として0~5が発生することになります。
④最後に関数「MOD()」の戻り値に1を加算することにより、サイコロの出目1~6が発生することになります。
※ このように、実務的には関数を単独で使用するより、いくつかの関数を組み合わせて求める値を算出することが一般的です。
条件分岐して戻り値を決定する関数
CASEWHEN関数やCASE関数は、指定した列の値によって条件分岐を行い、戻り値を決定する関数です。
CASEWHEN関数
<構文> CASEWHEN(<条件式>,<条件式が真の場合の戻り値>,<条件式が偽の場合の戻り値>)
<戻り値> 決定された戻り値
<SQL例4.21>
SELECT
“ID“,
”Name“,
“Gender“
CASEWHEN(“Gender“=’m’,’男性’,’女性’) AS “性別“
FROM “Staff“;
【<SQL例4.21>の実行結果】(一部)
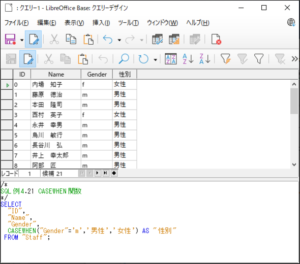
CASE関数(単一条件)
CASE関数で単一の条件で戻り値を分岐させる場合は、キーワード「CASE」の次に対象の列名を記述し、キーワード「WHEN」の次に列の値を指定します。そしてこれが分岐の条件となります。
<構文> CASE <対象の列名>
WHEN <値> THEN <値と一致する場合の戻り値>
ELSE <値と一致しない場合の戻り値>
END
<戻り値> 決定された戻り値
<SQL例4.22>
SELECT
“ID“,
“Name“,
“Gender“
CASE “Gender”
WHEN ’m’ THEN ’男性’
ELSE ’女性
END AS “性別“
FROM “Staff“;
【<SQL例4.22>の実行結果】(一部)
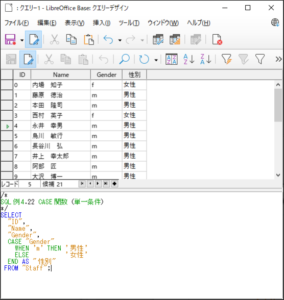
実行結果は<SQL例4.21>と同じになります。
CASE関数(複数条件)
CASE関数で複数の条件で戻り値を分岐させる場合はキーワード「CASE」の次に対象の列名を記述せず、キーワード「WHEN」の次に条件式を記述します。
CASEWHEN関数および前述の単一条件によるCASE関数の戻り値が、指定した値である場合とそうでない場合の二者択一形式であるのに対し、この構文ではWHEN句を複数記述することにより3つ以上の戻り値を設定することができます。
<構文> CASE
WHEN <条件式1> THEN <条件式1が真の場合の戻り値>
WHEN <条件式2> THEN <条件式2が真の場合の戻り値>
.
.
.
ELSE <どの条件式も偽の場合の戻り値>
END
<戻り値> 決定された戻り値
<SQL例4.23>
SELECT
“ID“,
“Name“,
CASE
WHEN “ID” IN (’D001’,’D002’,’D003’) THEN ’ドリンク’
WHEN “ID” LIKE ’S%’ THEN ’筆記具’
ELSE ’雑貨’
END AS “商品分類“
FROM “Item“;
※ 最初のキーワード「WHEN」では‘D001’、‘D002’、‘D003’の3つのいずれかの値をもつIDを条件付け、真の場合の戻り値を「ドリンク」とし、次のキーワード「WHEN」では先頭に「S」の付くIDをLIKE演算子(あいまい検索)で条件付け、真の場合の戻り値を「筆記具」とし、いずれも偽の場合の戻り値を「ELSE」で「雑貨」としています。
【<SQL例4.23>の実行結果】
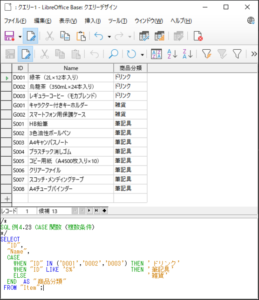
入れ子構造にしたCASE関数
CASE関数もまた入れ子構造にするこごができます。キーワード「THEN」の次に戻り値を指定するべきところを、その位置に別のCASE関数を記述することにより、同一条件の中でさらに条件分岐させることが可能になります。
<構文> CASE
WHEN <条件式1> THEN <別のCASE関数>
WHEN <条件式2> THEN <条件式2が真の場合の戻り値>
.
.
.
ELSE <どの条件式も偽の場合の戻り値>
END
<戻り値> 決定された戻り値
<SQL例4.24>
SELECT
“ID“,
“Name“,
CASE
WHEN “ID” IN (’D001’,’D002’,’D003’) THEN
CASE
WHEN “ID“=’D001’ THEN ’ドリンク(緑茶)’
WHEN “ID“=’D002’ THEN ’ドリンク(烏龍茶)’
ELSE ’ドリンク(コーヒー豆)’
END
WHEN “ID” LIKE ’S%’ THEN ’筆記具’
ELSE ’雑貨’
END AS “商品分類“
FROM “Item“;
※ 最初のキーワード「WHEN」では‘D001’、‘D002’、‘D003’の3つのいずれかの値をもつIDを条件付け、キーワード「THEN」の次に条件が真になった場合に適用される別のCASE関数を入れ子にして設定しています。
入れ子にしたCASE関数の最初のキーワード「WHEN」ではID=’D001′の場合の戻り値を「ドリンク(緑茶)」、次のキーワード「WHEN」ではID=’D002′の場合の戻り値を「ドリンク(烏龍茶)」とし、いずれも偽の場合の戻り値を「ドリンク(コーヒー豆)」としています。
それ以外の記述は<SQL例4.23>と同じです。
【<SQL例4.24>の実行結果】
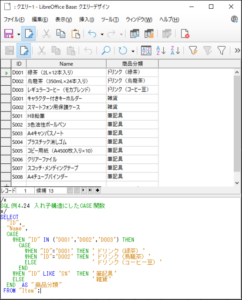
Null値を避けるCOALESCE関数
検索したデータにNull値があると、そのデータを活用する上で支障をきたす場合があります。そのような懸念がある場合はCOALESCE関数を使用して支障のない値に置き換える手法をとります。
ちなみに「COALESCE」は「コウアレス」と呼びます。
<構文> COALESCE(<列名>,<列名の値がNull値だった場合に置き換える値>)
<戻り値> 指定した列名の元の値、または置き換えられた値
<SQL例4.25>
SELECT
“ID“,
“Name“,
COALESCE(“Unit_ID“,’[Null Data]’) AS “単位ID“,
COALESCE(“UnitPrice“,0) AS “単価“,
COALESCE(“TaxRate“,0) AS “消費税率“
FROM “Item“;
(注)置き換える値は列のタイプに従った指定をします。つまり、文字タイプであればリテラル、数字タイプであれば数値を指定します。
【<SQL例4.25>の実行結果】
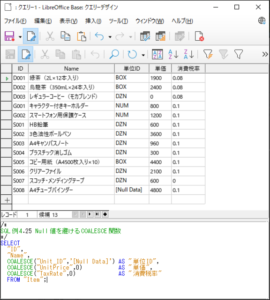
Null値のある行が指定した値に置き替えられているのが確認されます。